LiVeAction#
@inproceedings{jacobellis2026liveaction,
title={{LiVeAction}: Lightweight, Versatile, and Asymmetric Codec Design for Real-time Operation},
author={Jacobellis, Dan and Yadwadkar, Neeraja J.},
booktitle={IEEE Data Compression Conference (DCC)},
year={2026},
note={in press},
url={https://ut-sysml.github.io/liveaction}
}
import io, torch, datasets, numpy as np, matplotlib.pyplot as plt
import PIL.Image, pillow_jpls
from torchvision.transforms.v2.functional import pil_to_tensor, to_pil_image
from compressors.liveaction._codec import (
load_codec,
encode_to_blob,
decode_from_blob,
to_model_input,
from_model_output,
)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
dtype = torch.float32
print(f'device={device} dtype={dtype}')
device=cuda dtype=torch.float32
Load the codec#
codec, info = load_codec(
repo_id='danjacobellis/liveaction',
device=device,
torch_dtype=dtype,
)
print(f'short_name = {info.short_name}')
print(f'stride = {info.stride}')
print(f'latent_dim = {info.latent_dim}')
print(f'J = {info.J}')
short_name = lsdir_f16c48
stride = 16
latent_dim = 48
J = 4
Load a Kodak image#
dataset = datasets.load_dataset('danjacobellis/kodak', split='validation')
img = dataset[22]['image'].convert('RGB')
W, H = img.size
print(f'image size: {W} x {H} (divisible by 16: {W % 16 == 0 and H % 16 == 0})')
display(img)
image size: 768 x 512 (divisible by 16: True)

Analysis transform#
x_01 = pil_to_tensor(img).to(dtype).unsqueeze(0).to(device) / 255.0
x_in = to_model_input(x_01)
with torch.inference_mode():
z = codec.encode(x_in)
z_int = codec.quantize.compand(z).round()
print(f'continuous latent shape: {tuple(z.shape)}')
print(f'integer latent shape: {tuple(z_int.shape)}')
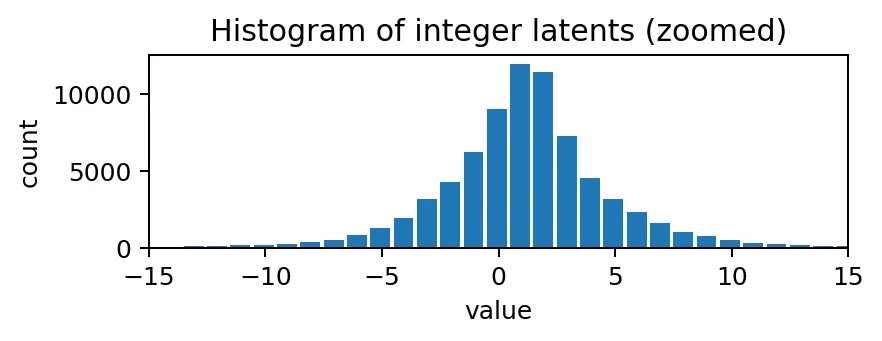
print(f'integer latent range: [{int(z_int.min())}, {int(z_int.max())}]')
plt.figure(figsize=(5, 2), dpi=180)
plt.hist(z_int.float().cpu().flatten(), range=(-127.5, 127.5), bins=255, width=0.85)
plt.xlim([-15, 15])
plt.title('Histogram of integer latents (zoomed)')
plt.xlabel('value')
plt.ylabel('count')
plt.tight_layout()
plt.show()
continuous latent shape: (1, 48, 32, 48)
integer latent shape: (1, 48, 32, 48)
integer latent range: [-25, 26]
Entropy coding (JPEG-LS)#
with torch.inference_mode():
blob, latent_hw = encode_to_blob(codec, x_in)
buff = io.BytesIO(blob)
n_bytes = len(buff.getbuffer())
bpp = 8 * n_bytes / (H * W)
print(f'latent (H, W): {latent_hw}')
print(f'compressed size: {n_bytes} bytes')
print(f'bpp: {bpp:.4f}')
latent (H, W): (32, 48)
compressed size: 29401 bytes
bpp: 0.5982
Latent as an RGB image#
packed = PIL.Image.open(io.BytesIO(buff.getvalue()))
packed.load()
print(f'packed RGB image size: {packed.size}')
display(packed)
print('zoomed (nearest-neighbor upsample to image size):')
display(packed.resize((W, H), resample=PIL.Image.Resampling.NEAREST))
packed RGB image size: (192, 128)

zoomed (nearest-neighbor upsample to image size):

Decode from the buffer#
with torch.inference_mode():
x_hat = decode_from_blob(
codec,
buff.getvalue(),
info.latent_dim,
device,
dtype,
).clamp(-1, 1)
x_hat_01 = from_model_output(x_hat).clamp(0, 1)
psnr = -10 * torch.nn.functional.mse_loss(x_01, x_hat_01).log10().item()
print(f'bpp = {bpp:.4f}')
print(f'PSNR = {psnr:.2f} dB')
bpp = 0.5982
PSNR = 35.62 dB
Reconstruction#
display(to_pil_image(x_hat_01[0].cpu()))
