DGML#
@inproceedings{cheng2020learned,
title={Learned image compression with discretized gaussian mixture likelihoods and attention modules},
author={Cheng, Zhengxue and Sun, Heming and Takeuchi, Masaru and Katto, Jiro},
booktitle={CVPR},
year={2020}
}
import io, struct, zlib
import numpy as np
import torch
import torch.nn.functional as F
import datasets
import matplotlib.pyplot as plt
import PIL.Image
from torchvision.transforms.v2.functional import to_pil_image
from compressors.compressai_baselines.zoo import cheng2020_anchor
torch.set_num_threads(1)
device = 'cpu' # the codec runs on CPU; the eval harness convention
Load the codec#
quality = 3
model = cheng2020_anchor(quality=quality, pretrained=True, progress=False)
model.eval().to(device)
n_params = sum(p.numel() for p in model.parameters())
print(f"cheng2020-anchor (quality={quality}) N=M={model.N} params={n_params/1e6:.2f} M")
cheng2020-anchor (quality=3) N=M=128 params=11.83 M
Load a Kodak image#
dataset = datasets.load_dataset("danjacobellis/kodak", split="validation")
img_idx = 22
img_pil = dataset[img_idx]['image'].convert("RGB")
print(f"Kodak[{img_idx}] size = {img_pil.size}")
display(img_pil)
Kodak[22] size = (768, 512)

Preprocessing#
def pil_to_01_tensor(img):
arr = np.asarray(img.convert("RGB")).astype("float32") / 255.0
return torch.from_numpy(arr).permute(2, 0, 1).contiguous().unsqueeze(0)
def pad_to_multiple(t, multiple):
H, W = t.shape[-2:]
pH = (multiple - H % multiple) % multiple
pW = (multiple - W % multiple) % multiple
return F.pad(t, (0, pW, 0, pH), mode="replicate"), (H, W)
x = pil_to_01_tensor(img_pil).to(device)
H_orig, W_orig = x.shape[-2:]
n_pixels = H_orig * W_orig
x_pad, _ = pad_to_multiple(x, 64)
print(f"native HxW = {H_orig}x{W_orig}; padded = {x_pad.shape[-2]}x{x_pad.shape[-1]}; n_pixels = {n_pixels}")
native HxW = 512x768; padded = 512x768; n_pixels = 393216
Forward pass#
with torch.no_grad():
out = model(x_pad)
bpp_theoretical = sum(
float((-torch.log2(lk)).sum().item())
for lk in out['likelihoods'].values()
) / n_pixels
print(f"bpp_theoretical = {bpp_theoretical:.4f}")
bpp_theoretical = 0.1129
Per-channel bit cost#
y_lk = out['likelihoods']['y']
per_ch_bits_y = (-torch.log2(y_lk)).sum(dim=(0, 2, 3)).cpu().numpy()
per_ch_bpp_y = per_ch_bits_y / n_pixels
fig, ax = plt.subplots(figsize=(8, 3))
ax.bar(np.arange(per_ch_bpp_y.size), per_ch_bpp_y, width=1.0, color="#3a7ca5")
ax.set_xlabel("y channel index")
ax.set_ylabel("bpp")
ax.set_title("Per-channel bpp contribution from latent y")
ax.set_xlim(-0.5, per_ch_bpp_y.size - 0.5)
ax.grid(True, alpha=0.3, axis="y")
fig.tight_layout()
plt.show()
top5 = np.argsort(-per_ch_bpp_y)[:5]
print("Top-5 most expensive y channels:")
for i in top5:
print(f" ch {int(i):3d} bpp = {float(per_ch_bpp_y[i]):.5f}")
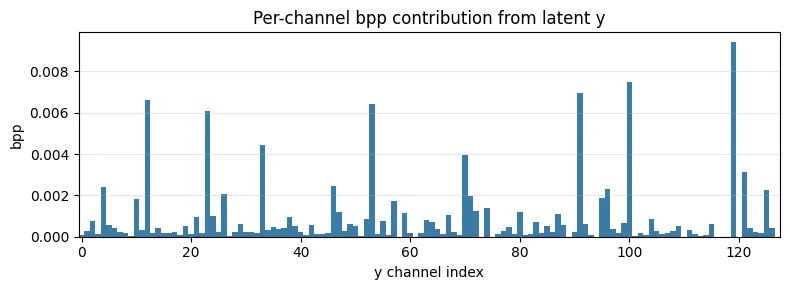
Top-5 most expensive y channels:
ch 119 bpp = 0.00941
ch 100 bpp = 0.00746
ch 91 bpp = 0.00694
ch 12 bpp = 0.00662
ch 53 bpp = 0.00644
Top-K latent feature maps#
with torch.no_grad():
y_pre = model.g_a(x_pad)
top_k = 16
top_idx = np.argsort(-per_ch_bpp_y)[:top_k]
ncols = 4
nrows = top_k // ncols
fig, axes = plt.subplots(nrows, ncols, figsize=(ncols * 2.0, nrows * 1.4))
for ax, ch in zip(axes.flat, top_idx):
fmap = y_pre[0, int(ch)].cpu().numpy()
ax.imshow(fmap, cmap="gray")
ax.set_title(f"ch {int(ch)}", fontsize=8)
ax.axis("off")
fig.suptitle(f"Top-{top_k} y channels by bit cost (pre-quantization)", fontsize=10)
fig.tight_layout()
plt.show()

Encode: extract integer latents#
with torch.no_grad():
y = model.g_a(x_pad)
z = model.h_a(y)
z_hat, _ = model.entropy_bottleneck(z)
gaussian_params = model.h_s(z_hat)
scales_hat, means_hat = gaussian_params.chunk(2, 1)
y_hat, _ = model.gaussian_conditional(y, scales_hat, means=means_hat)
print(f"y_hat shape = {tuple(y_hat.shape)} range = [{y_hat.min().item():+.2f}, {y_hat.max().item():+.2f}]")
print(f"z_hat shape = {tuple(z_hat.shape)} range = [{z_hat.min().item():+.2f}, {z_hat.max().item():+.2f}]")
y_hat shape = (1, 128, 32, 48) range = [-24.86, +63.98]
z_hat shape = (1, 128, 8, 12) range = [-5.54, +3.46]
Pack into a byte buffer#
y_int = y_hat.detach().cpu().to(torch.int16).numpy()
z_int = z_hat.detach().cpu().to(torch.int16).numpy()
buff = io.BytesIO()
buff.write(struct.pack("<8i", *y_int.shape, *z_int.shape)) # N C H W N C H W
buff.write(y_int.tobytes())
buff.write(z_int.tobytes())
bpp_buffer_raw = 8 * len(buff.getbuffer()) / n_pixels
# Honest middle-ground rate: pipe the same buffer through zlib.
payload_z = zlib.compress(buff.getvalue(), 9)
bpp_buffer_zlib = 8 * len(payload_z) / n_pixels
print(f"buffer size = {len(buff.getbuffer()):>8d} bytes")
print(f"zlib(level=9) = {len(payload_z):>8d} bytes")
print()
print(f"bpp_theoretical = {bpp_theoretical:.4f} (entropy lower bound)")
print(f"bpp_buffer_raw = {bpp_buffer_raw:.4f} ({bpp_buffer_raw/bpp_theoretical:.1f}x of theoretical)")
print(f"bpp_buffer_zlib = {bpp_buffer_zlib:.4f} ({bpp_buffer_zlib/bpp_theoretical:.1f}x of theoretical)")
buffer size = 417824 bytes
zlib(level=9) = 16908 bytes
bpp_theoretical = 0.1129 (entropy lower bound)
bpp_buffer_raw = 8.5007 (75.3x of theoretical)
bpp_buffer_zlib = 0.3440 (3.0x of theoretical)
Decode from the buffer#
buff.seek(0)
y_shape = struct.unpack("<4i", buff.read(16))
z_shape = struct.unpack("<4i", buff.read(16))
y_n = np.frombuffer(buff.read(int(np.prod(y_shape)) * 2), dtype=np.int16).reshape(y_shape)
z_n = np.frombuffer(buff.read(int(np.prod(z_shape)) * 2), dtype=np.int16).reshape(z_shape)
y_hat_decoded = torch.from_numpy(y_n.copy()).float().to(device)
with torch.no_grad():
x_hat_padded = model.g_s(y_hat_decoded)
x_hat = x_hat_padded[..., :H_orig, :W_orig].clamp(0.0, 1.0)
mse = F.mse_loss(x[..., :H_orig, :W_orig], x_hat).item()
psnr = -10 * np.log10(mse) if mse > 0 else float('inf')
print(f"PSNR (buffer-decoded) = {psnr:.2f} dB")
PSNR (buffer-decoded) = 30.86 dB
Original / reconstruction / difference#
orig_np = x[0, :, :H_orig, :W_orig].cpu().permute(1, 2, 0).numpy()
recon_np = x_hat[0].cpu().permute(1, 2, 0).numpy()
diff_np = np.clip(np.abs(orig_np - recon_np) * 8.0, 0.0, 1.0)
fig, axes = plt.subplots(1, 3, figsize=(13, 4.5))
for ax, im, title in zip(
axes,
[orig_np, recon_np, diff_np],
["original",
f"reconstruction (PSNR = {psnr:.2f} dB)",
"|x − x̂| × 8"],
):
ax.imshow(im)
ax.set_title(title, fontsize=10)
ax.axis("off")
fig.tight_layout()
plt.show()

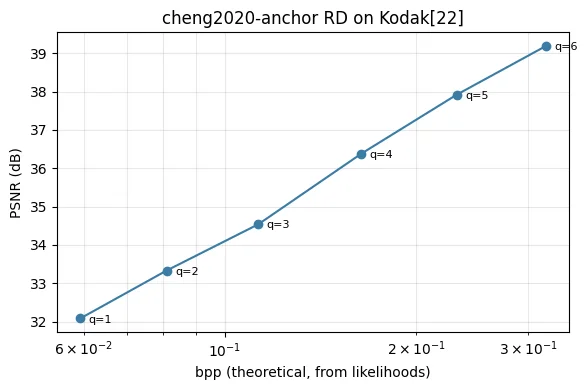
Rate-distortion staircase#
rd_points = []
for q in [1, 2, 3, 4, 5, 6]:
m = cheng2020_anchor(quality=q, pretrained=True, progress=False).eval().to(device)
with torch.no_grad():
out_q = m(x_pad)
bpp_q = sum(
float((-torch.log2(lk)).sum().item())
for lk in out_q['likelihoods'].values()
) / n_pixels
x_hat_q = out_q['x_hat'][..., :H_orig, :W_orig].clamp(0.0, 1.0)
mse_q = F.mse_loss(x[..., :H_orig, :W_orig], x_hat_q).item()
psnr_q = -10 * np.log10(mse_q) if mse_q > 0 else float('inf')
rd_points.append((q, bpp_q, psnr_q))
print(f" q={q} N={m.N} bpp={bpp_q:.4f} PSNR={psnr_q:.2f} dB")
del m
bpps = [p[1] for p in rd_points]
psnrs = [p[2] for p in rd_points]
fig, ax = plt.subplots(figsize=(6, 4))
ax.semilogx(bpps, psnrs, 'o-', color="#3a7ca5")
for q, b, p in rd_points:
ax.annotate(f"q={q}", (b, p), textcoords="offset points", xytext=(6, -3), fontsize=8)
ax.set_xlabel("bpp (theoretical, from likelihoods)")
ax.set_ylabel("PSNR (dB)")
ax.set_title(f"cheng2020-anchor RD on Kodak[{img_idx}]")
ax.grid(True, alpha=0.3, which="both")
fig.tight_layout()
plt.show()
q=1 N=128 bpp=0.0592 PSNR=32.08 dB
q=2 N=128 bpp=0.0810 PSNR=33.33 dB
q=3 N=128 bpp=0.1129 PSNR=34.54 dB
q=4 N=192 bpp=0.1640 PSNR=36.38 dB
q=5 N=192 bpp=0.2318 PSNR=37.92 dB
q=6 N=192 bpp=0.3202 PSNR=39.19 dB