WaLLoC#
@inproceedings{jacobellis2025learned,
title={Learned Compression for Compressed Learning},
author={Jacobellis, Dan and Yadwadkar, Neeraja J.},
booktitle={Data Compression Conference},
year={2025},
organization={IEEE}
}
import io
import torch
import matplotlib.pyplot as plt
import PIL.Image
from datasets import load_dataset
from torchvision.transforms.v2.functional import pil_to_tensor, to_pil_image
from compressors.walloc._codec import (
load_codec,
encode_to_latent,
decode_from_blob,
latent_to_webp_bytes,
to_model_input,
from_model_output,
)
device = 'cpu'
torch_dtype = torch.float32
Load the codec#
codec, info = load_codec(device=device, torch_dtype=torch_dtype)
print(f'channels = {info.channels}')
print(f'J (wavelet depth) = {info.J}')
print(f'latent_dim = {info.latent_dim}')
print(f'latent_bits = {info.latent_bits}')
print(f'dimensionality_reduction = {info.dimensionality_reduction:.2f}x')
print(f'input_range = {info.input_range} # [-0.5, 0.5]')
Skipping import of cpp extensions due to incompatible torch version 2.11.0+cu130 for torchao version 0.15.0 Please see https://github.com/pytorch/ao/issues/2919 for more info
/home/dgj335/g/lib/python3.12/site-packages/pytorch_wavelets/dtcwt/coeffs.py:7: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import resource_stream
channels = 3
J (wavelet depth) = 3
latent_dim = 12
latent_bits = 8
dimensionality_reduction = 16.00x
input_range = centered # [-0.5, 0.5]
Load a Kodak image#
dataset = load_dataset('danjacobellis/kodak', split='validation')
img_pil = dataset[22]['image'].convert('RGB')
W, H = img_pil.size
n_pixels = H * W
print(f'image size = {W}x{H} (H % 8 = {H % 8}, W % 8 = {W % 8})')
img_pil
image size = 768x512 (H % 8 = 0, W % 8 = 0)

x_01 = pil_to_tensor(img_pil).to(torch_dtype).to(device).unsqueeze(0) / 255.0
x_in = to_model_input(x_01)
print(f'x_01 range = [{x_01.min():.3f}, {x_01.max():.3f}]')
print(f'x_in range = [{x_in.min():.3f}, {x_in.max():.3f}] shape = {tuple(x_in.shape)}')
x_01 range = [0.000, 1.000]
x_in range = [-0.500, 0.500] shape = (1, 3, 512, 768)
Wavelet analysis#
with torch.inference_mode():
X = codec.wavelet_analysis(x_in, J=codec.J)
print(f'X shape = {tuple(X.shape)} (expected: 1, 3 * 4**J = 192, H/8, W/8)')
X shape = (1, 192, 64, 96) (expected: 1, 3 * 4**J = 192, H/8, W/8)
Encode and round#
with torch.inference_mode():
z = codec.encoder[0:2](X) # continuous latent
z_hat = codec.encoder[2](z) # rounded integer latent
print(f'z shape = {tuple(z.shape)}')
print(f'z range = [{z.min():.2f}, {z.max():.2f}]')
print(f'z_hat shape = {tuple(z_hat.shape)} (1, latent_dim, H/8, W/8)')
print(f'z_hat range = [{z_hat.min().item():.0f}, {z_hat.max().item():.0f}] '
f'(integer-valued, dtype={z_hat.dtype})')
z shape = (1, 12, 64, 96)
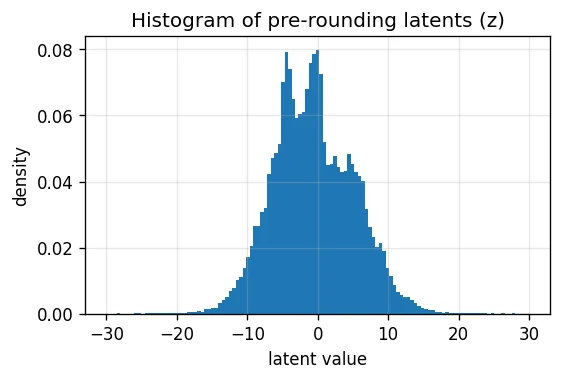
z range = [-28.90, 32.35]
z_hat shape = (1, 12, 64, 96) (1, latent_dim, H/8, W/8)
z_hat range = [-29, 32] (integer-valued, dtype=torch.float32)
plt.figure(figsize=(5, 3), dpi=120)
plt.hist(z.flatten().cpu().numpy(), bins=121, range=(-30, 30), density=True)
plt.title('Histogram of pre-rounding latents (z)')
plt.xlabel('latent value')
plt.ylabel('density')
plt.grid(alpha=0.3)
plt.show()
Pack to bytes (WebP-lossless)#
blob = latent_to_webp_bytes(z_hat, info.latent_bits)
buff = io.BytesIO(blob)
bpp = 8 * len(buff.getbuffer()) / n_pixels
print(f'len(buff) = {len(buff.getbuffer())} bytes')
print(f'bpp = {bpp:.4f}')
print(f'compression ratio = {24 / bpp:.2f}x (vs 24-bit RGB)')
len(buff) = 23276 bytes
bpp = 0.4736
compression ratio = 50.68x (vs 24-bit RGB)
Visualize the packed latent#
def scale_for_display(img, n_bits):
"""Rescale an n_bits-quantized PIL image to fill 8-bit display range."""
scale_factor = (2 ** 8 - 1) / (2 ** n_bits - 1)
lut = [int(i * scale_factor) for i in range(2 ** n_bits)]
channels = img.split()
scaled = [ch.point(lut * 2 ** (8 - n_bits)) for ch in channels]
return PIL.Image.merge(img.mode, scaled)
latent_pil = PIL.Image.open(io.BytesIO(blob))
print(f'latent image: size = {latent_pil.size}, mode = {latent_pil.mode}')
scale_for_display(latent_pil, info.latent_bits)
latent image: size = (192, 128), mode = RGB

Decode from the buffer#
X_hat = decode_from_blob(
codec, buff.getvalue(), info.latent_dim, info.latent_bits,
device, torch_dtype,
)
x_hat = from_model_output(X_hat).clamp(0, 1)
print(f'X_hat range = [{X_hat.min():.3f}, {X_hat.max():.3f}] '
f'(decoder output, approx [-0.5, 0.5]; outliers clamped below)')
print(f'x_hat range = [{x_hat.min():.3f}, {x_hat.max():.3f}] '
f'(after from_model_output + clamp, [0, 1])')
print(f'x_hat shape = {tuple(x_hat.shape)}')
X_hat range = [-0.699, 0.568] (decoder output, approx [-0.5, 0.5]; outliers clamped below)
x_hat range = [0.000, 1.000] (after from_model_output + clamp, [0, 1])
x_hat shape = (1, 3, 512, 768)
Reconstruction and PSNR#
mse = torch.nn.functional.mse_loss(x_01, x_hat).item()
psnr = -10 * torch.log10(torch.tensor(mse)).item()
print(f'bpp = {bpp:.4f}')
print(f'PSNR = {psnr:.2f} dB')
to_pil_image(x_hat[0].cpu())
bpp = 0.4736
PSNR = 34.24 dB

Sanity: codec.forward matches the manual pipeline#
with torch.inference_mode():
x_hat_fwd, _, _ = codec(x_in) # in [-0.5, 0.5]
x_hat_fwd_01 = from_model_output(x_hat_fwd).clamp(0, 1)
max_diff = (x_hat_fwd_01 - x_hat).abs().max().item()
print(f'max | codec.forward - manual decode | = {max_diff:.6e}')
max | codec.forward - manual decode | = 0.000000e+00