mbt2018#
@inproceedings{minnen2018joint,
title={Joint autoregressive and hierarchical priors for learned image compression},
author={Minnen, David and Ball{\'e}, Johannes and Toderici, George D.},
booktitle={NeurIPS},
year={2018}
}
import io, struct, zlib, math
import numpy as np
import torch
import torch.nn.functional as F
import datasets
import matplotlib.pyplot as plt
import PIL.Image
from torchvision.transforms.v2.functional import pil_to_tensor, to_pil_image
from compressors.compressai_baselines.zoo import mbt2018
device = 'cpu' # vendored slice is CPU-only by convention
torch.set_num_threads(1)
quality = 4 # mid-rate point on the native q in {1..8} grid
Load the codec#
model = mbt2018(quality=quality, pretrained=True, progress=False).eval().to(device)
print(f"N={model.N} M={model.M} downsampling_factor={model.downsampling_factor}")
N=192 M=192 downsampling_factor=64
Load a Kodak image#
dataset = datasets.load_dataset('danjacobellis/kodak', split='validation')
img_pil = dataset[19]['image'].convert('RGB')
W, H = img_pil.size
n_pixels = H * W
print(f'{W} x {H} ({n_pixels} px)')
img_pil
768 x 512 (393216 px)

x = (pil_to_tensor(img_pil).to(torch.float32) / 255.0).unsqueeze(0).to(device)
def pad_to_multiple(x, multiple=64):
h, w = x.shape[-2:]
ph = (multiple - h % multiple) % multiple
pw = (multiple - w % multiple) % multiple
if ph == 0 and pw == 0:
return x, (h, w)
return F.pad(x, (0, pw, 0, ph), mode='replicate'), (h, w)
x_pad, (oh, ow) = pad_to_multiple(x, 64)
print(f'x_pad shape: {tuple(x_pad.shape)} original (H,W)=({oh},{ow})')
x_pad shape: (1, 3, 512, 768) original (H,W)=(512,768)
Forward pass#
with torch.no_grad():
out = model(x_pad)
x_hat_fwd = out['x_hat'][..., :oh, :ow].clamp(0.0, 1.0)
mse_fwd = F.mse_loss(x, x_hat_fwd).item()
psnr_fwd = -10 * math.log10(mse_fwd) if mse_fwd > 0 else float('inf')
bits_y = float((-torch.log2(out['likelihoods']['y'])).sum().item())
bits_z = float((-torch.log2(out['likelihoods']['z'])).sum().item())
bpp_theoretical = (bits_y + bits_z) / n_pixels
print(f'reconstruction PSNR = {psnr_fwd:.2f} dB')
print(f'bpp_theoretical = {bpp_theoretical:.4f} '
f'(y={bits_y/n_pixels:.4f} z={bits_z/n_pixels:.4f})')
reconstruction PSNR = 34.72 dB
bpp_theoretical = 0.2440 (y=0.2396 z=0.0043)
Reconstruction and residual#
diff = ((x - x_hat_fwd).abs() * 10).clamp(0.0, 1.0)
fig, axes = plt.subplots(1, 3, figsize=(13, 4))
for ax, im, title in zip(
axes,
[x[0].cpu(), x_hat_fwd[0].cpu(), diff[0].cpu()],
['original', f'mbt2018 q={quality}', 'abs residual ×10'],
):
ax.imshow(im.permute(1, 2, 0).numpy())
ax.set_title(title)
ax.axis('off')
plt.tight_layout(); plt.show()

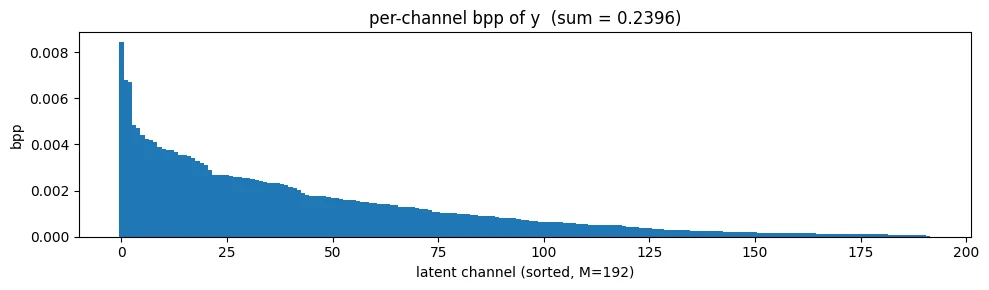
Per-channel rate#
y_lik = out['likelihoods']['y'] # (1, M, H', W')
per_ch_bpp = (-torch.log2(y_lik)).sum(dim=(0, 2, 3)).cpu().numpy() / n_pixels
order = np.argsort(per_ch_bpp)[::-1]
fig, ax = plt.subplots(figsize=(10, 3))
ax.bar(range(len(per_ch_bpp)), per_ch_bpp[order], width=1.0)
ax.set_xlabel(f'latent channel (sorted, M={model.M})')
ax.set_ylabel('bpp')
ax.set_title(f'per-channel bpp of y (sum = {per_ch_bpp.sum():.4f})')
plt.tight_layout(); plt.show()
Latent mosaic#
with torch.no_grad():
y_pre = model.g_a(x_pad)
y_pre_hat = model.gaussian_conditional.quantize(y_pre, 'dequantize')
yh = y_pre_hat[0].cpu().numpy() # (M, H', W')
M, Hp, Wp = yh.shape
cols = int(np.ceil(np.sqrt(M)))
rows = int(np.ceil(M / cols))
mosaic = np.zeros((rows * Hp, cols * Wp), dtype=np.float32)
for k in range(M):
r, c = divmod(k, cols)
tile = yh[k]
lo, hi = tile.min(), tile.max()
norm = (tile - lo) / (hi - lo + 1e-8)
mosaic[r*Hp:(r+1)*Hp, c*Wp:(c+1)*Wp] = norm
fig, ax = plt.subplots(figsize=(8, 8 * rows / cols))
ax.imshow(mosaic, cmap='gray')
ax.set_title(f'y_hat mosaic ({M} channels, {Hp}×{Wp} each, per-tile normalized)')
ax.axis('off')
plt.tight_layout(); plt.show()

Encode and pack to a buffer#
with torch.no_grad():
y = model.g_a(x_pad)
z = model.h_a(y)
z_hat, _ = model.entropy_bottleneck(z) # eval-mode rounding
y_hat = model.gaussian_conditional.quantize(y, 'dequantize')
print(f'y_hat shape={tuple(y_hat.shape)} range=[{int(y_hat.min())}, {int(y_hat.max())}]')
print(f'z_hat shape={tuple(z_hat.shape)} range=[{int(z_hat.min())}, {int(z_hat.max())}]')
y_hat shape=(1, 192, 32, 48) range=[-51, 91]
z_hat shape=(1, 192, 8, 12) range=[-6, 11]
y_int = y_hat.detach().cpu().to(torch.int16).numpy()
z_int = z_hat.detach().cpu().to(torch.int16).numpy()
buff = io.BytesIO()
buff.write(struct.pack('<8i', *y_int.shape, *z_int.shape))
buff.write(y_int.tobytes())
buff.write(z_int.tobytes())
bpp_buffer_raw = 8 * len(buff.getbuffer()) / n_pixels
header = struct.pack('<8i', *y_int.shape, *z_int.shape)
zpayload = zlib.compress(y_int.tobytes() + z_int.tobytes(), 9)
bpp_buffer_zlib = 8 * (len(header) + len(zpayload)) / n_pixels
print(f'bpp_theoretical = {bpp_theoretical:.4f} (likelihood lower bound)')
print(f'bpp_buffer_zlib = {bpp_buffer_zlib:.4f} (header + zlib(int16 payload))')
print(f'bpp_buffer_raw = {bpp_buffer_raw:.4f} ({len(buff.getbuffer())} bytes raw int16)')
bpp_theoretical = 0.2440 (likelihood lower bound)
bpp_buffer_zlib = 0.6954 (header + zlib(int16 payload))
bpp_buffer_raw = 12.7507 (626720 bytes raw int16)
Decode from buff#
buff.seek(0)
y_shape = struct.unpack('<4i', buff.read(16))
z_shape = struct.unpack('<4i', buff.read(16))
n_y, n_z = int(np.prod(y_shape)), int(np.prod(z_shape))
y_arr = np.frombuffer(buff.read(n_y * 2), dtype=np.int16).reshape(y_shape)
z_arr = np.frombuffer(buff.read(n_z * 2), dtype=np.int16).reshape(z_shape)
y_hat_dec = torch.from_numpy(y_arr.copy()).float().to(device)
with torch.no_grad():
x_hat_dec = model.g_s(y_hat_dec)[..., :oh, :ow].clamp(0.0, 1.0)
# Sanity: this is the exact same y_hat the forward pass used internally,
# so the reconstruction must match x_hat_fwd to numerical precision.
max_drift = (x_hat_dec - x_hat_fwd).abs().max().item()
print(f'max |x_hat_dec - x_hat_fwd| = {max_drift:.2e} (should be ~0)')
mse_dec = F.mse_loss(x, x_hat_dec).item()
psnr_dec = -10 * math.log10(mse_dec) if mse_dec > 0 else float('inf')
print(f'PSNR = {psnr_dec:.2f} dB @ bpp_buffer_zlib = {bpp_buffer_zlib:.4f}')
max |x_hat_dec - x_hat_fwd| = 0.00e+00 (should be ~0)
PSNR = 34.72 dB @ bpp_buffer_zlib = 0.6954
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
axes[0].imshow(x[0].cpu().permute(1, 2, 0).numpy())
axes[0].set_title('original')
axes[0].axis('off')
axes[1].imshow(x_hat_dec[0].cpu().permute(1, 2, 0).numpy())
axes[1].set_title(f'decoded from buff (PSNR={psnr_dec:.2f} dB)')
axes[1].axis('off')
plt.tight_layout(); plt.show()

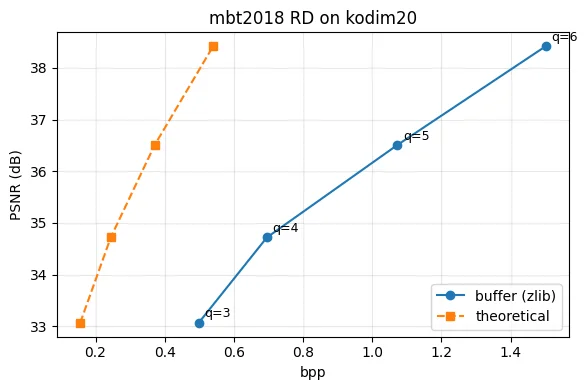
Rate-distortion staircase#
rd = [] # (bpp_zlib, psnr, q)
for q in [3, 4, 5, 6]:
m = mbt2018(quality=q, pretrained=True, progress=False).eval().to(device)
with torch.no_grad():
o = m(x_pad)
yq = m.g_a(x_pad)
zq = m.h_a(yq)
zqh, _ = m.entropy_bottleneck(zq)
yqh = m.gaussian_conditional.quantize(yq, 'dequantize')
xhat_q = o['x_hat'][..., :oh, :ow].clamp(0.0, 1.0)
psnr_q = -10 * math.log10(F.mse_loss(x, xhat_q).item())
yi = yqh.detach().cpu().to(torch.int16).numpy()
zi = zqh.detach().cpu().to(torch.int16).numpy()
hdr = struct.pack('<8i', *yi.shape, *zi.shape)
zp = zlib.compress(yi.tobytes() + zi.tobytes(), 9)
bpp_q = 8 * (len(hdr) + len(zp)) / n_pixels
bits_q = sum(float((-torch.log2(lk)).sum().item()) for lk in o['likelihoods'].values())
bpp_th_q = bits_q / n_pixels
rd.append((bpp_q, psnr_q, bpp_th_q, q))
print(f'q={q} bpp_th={bpp_th_q:.4f} bpp_zlib={bpp_q:.4f} PSNR={psnr_q:.2f} dB')
del m
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot([r[0] for r in rd], [r[1] for r in rd], 'o-', label='buffer (zlib)')
ax.plot([r[2] for r in rd], [r[1] for r in rd], 's--', label='theoretical')
for bpp_q, psnr_q, _, q in rd:
ax.annotate(f'q={q}', (bpp_q, psnr_q), xytext=(4, 4), textcoords='offset points', fontsize=9)
ax.set_xlabel('bpp')
ax.set_ylabel('PSNR (dB)')
ax.set_title('mbt2018 RD on kodim20')
ax.grid(True, alpha=0.3)
ax.legend()
plt.tight_layout(); plt.show()
q=3 bpp_th=0.1556 bpp_zlib=0.4982 PSNR=33.07 dB
q=4 bpp_th=0.2440 bpp_zlib=0.6954 PSNR=34.72 dB
q=5 bpp_th=0.3709 bpp_zlib=1.0723 PSNR=36.51 dB
q=6 bpp_th=0.5401 bpp_zlib=1.5019 PSNR=38.42 dB